
Clusterizzare i dati: cosa vuol dire e quali sono i vantaggi per un'azienda
17/06/2026
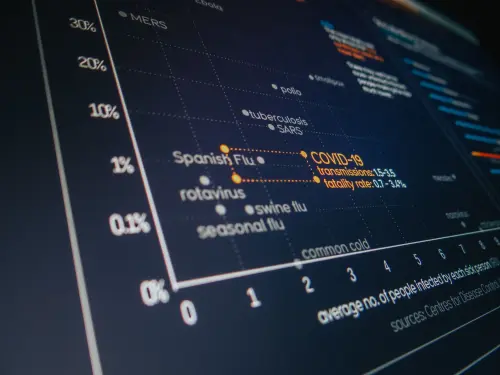
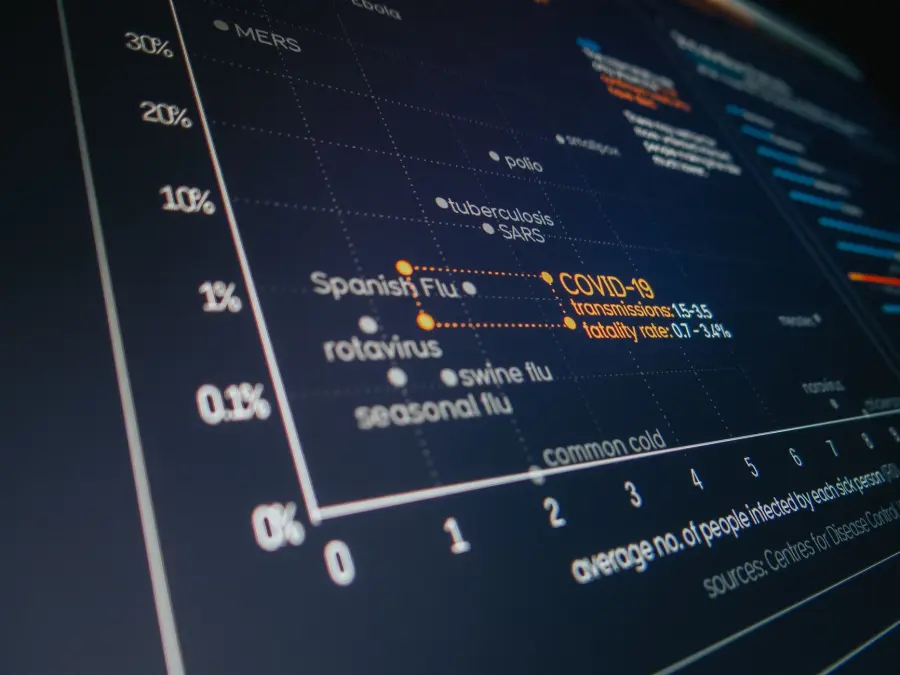
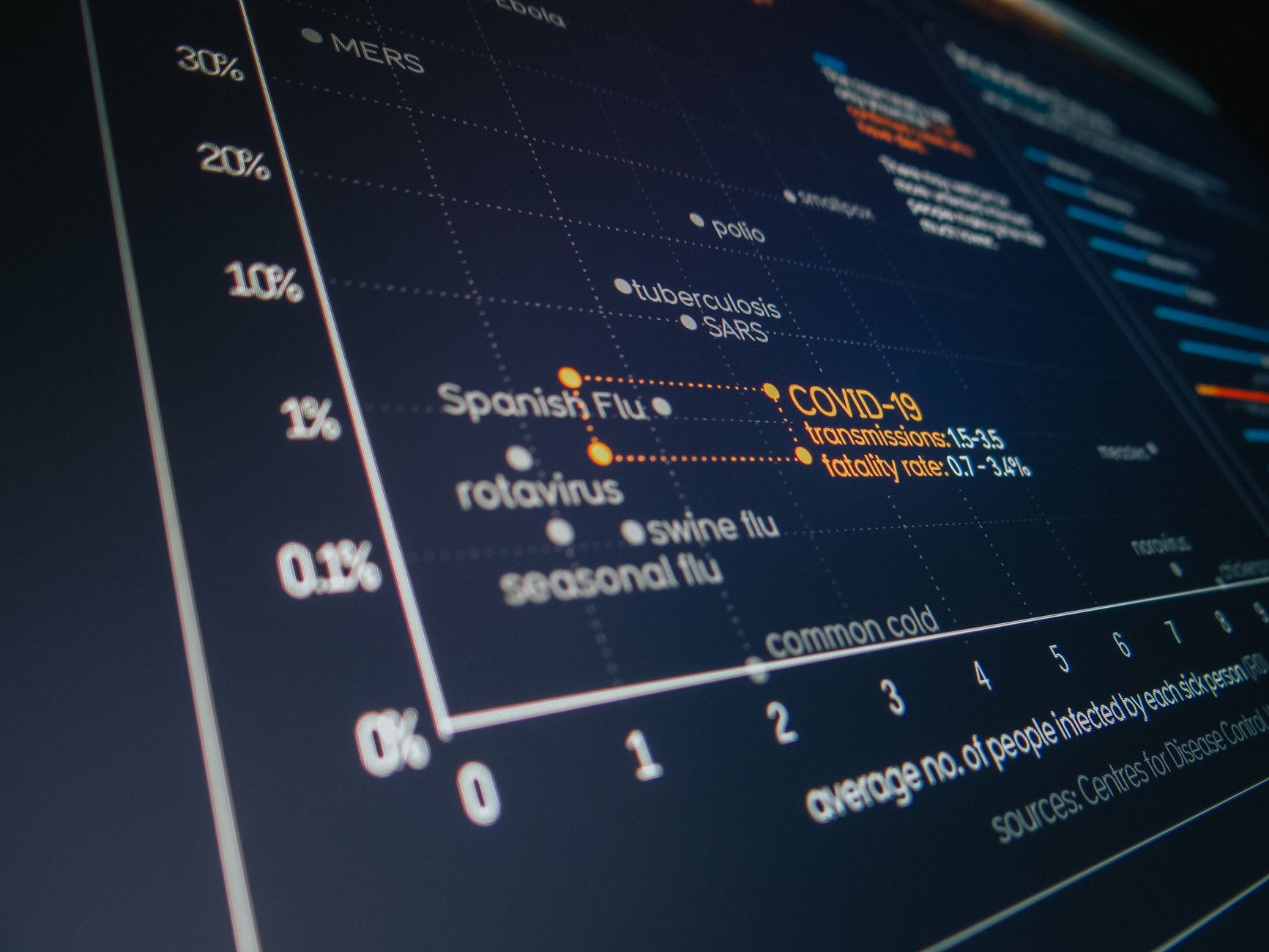
Quando un'impresa raccoglie dati su clienti, transazioni, comportamenti d'acquisto o performance operative, si trova quasi sempre di fronte a una massa indistinta di osservazioni che, prese singolarmente, dicono poco e, aggregate in modo grezzo, dicono ancora meno.
Clusterizzare i dati, termine che deriva dall'inglese cluster, gruppo o aggregato, significa applicare algoritmi statistici o di apprendimento automatico per suddividere un insieme di osservazioni in sottogruppi omogenei al loro interno ed eterogenei tra loro, secondo criteri definiti dalla struttura stessa dei dati, non da categorie imposte a priori dall'analista. Comprendere il clusterizzare significato non è un esercizio terminologico: è il punto di partenza per capire perché certe analisi producono insight utili e altre producono solo tabelle ben formattate.
La distinzione rispetto alla classificazione tradizionale è sostanziale: in un modello supervisionato, si parte da etichette note e si addestra un algoritmo a riconoscerle; nella clusterizzazione, che è una tecnica non supervisionata, le etichette non esistono in partenza emergono dai dati stessi. Questo implica che il processo richiede una fase interpretativa umana successiva all'elaborazione algoritmica: l'algoritmo identifica i gruppi, ma spetta all'analista o al decisore aziendale attribuire loro un significato funzionale, economico o strategico. È proprio in questa tensione tra automatizzazione e interpretazione che risiede il valore reale della tecnica, e anche il rischio principale di un suo uso superficiale.
Per le imprese che operano con volumi significativi di dati e nel 2026 è difficile trovare organizzazioni di medie dimensioni che non lo facciano la clusterizzazione è diventata uno strumento analitico trasversale, applicabile al marketing, alla logistica, alla gestione del rischio, all'ottimizzazione dei processi produttivi e all'analisi delle risorse umane. La questione non è se valga la pena adottarla, ma come farlo con rigore metodologico sufficiente a produrre risultati affidabili e non fuorvianti.
Principi algoritmici e varietà di approcci alla clusterizzazione
Tra gli algoritmi di clustering più diffusi in contesti aziendali, K-Means rimane il punto di riferimento operativo per la sua semplicità interpretativa e la scalabilità su dataset di grandi dimensioni: l'analista definisce il numero di cluster k, l'algoritmo assegna iterativamente ogni osservazione al centroide più vicino e aggiorna i centroidi fino a convergenza, minimizzando la varianza intra-cluster. Il limite più rilevante di K-Means è la sensibilità alla scelta iniziale dei centroidi e l'assunzione implicita che i cluster abbiano forma approssimativamente sferica e dimensione simile — condizioni che i dati aziendali reali rispettano raramente in modo ideale.
Gli algoritmi gerarchici, sia nella variante agglomerativa che divisiva, costruiscono invece una struttura ad albero, il dendrogramma, che permette di esplorare diverse granularità di segmentazione senza fissare a priori il numero di gruppi; questo li rende particolarmente utili nelle fasi esplorative, quando l'obiettivo è capire la struttura latente dei dati prima di definire quanti segmenti siano operativamente gestibili.
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) adotta un approccio diverso ancora: identifica cluster come regioni di alta densità separati da zone di bassa densità, trattando le osservazioni isolate come rumore; è efficace per dataset con cluster di forma irregolare e per l'identificazione di anomalie, ma richiede una calibrazione attenta dei parametri di densità. Conoscere queste differenze non è un dettaglio tecnico secondario: la scelta dell'algoritmo condiziona direttamente il tipo di struttura che si riesce a rilevare, e applicare K-Means su dati con distribuzioni complesse significa introdurre distorsioni sistematiche nei risultati.
Preparazione dei dati e scelte metodologiche preliminari
La qualità di un'analisi di clustering dipende in misura determinante dalle operazioni condotte prima dell'applicazione dell'algoritmo, in una fase che nella pratica professionale occupa spesso più tempo dell'elaborazione stessa: normalizzazione delle variabili, gestione dei valori mancanti, riduzione della dimensionalità e selezione delle feature rilevanti sono passaggi che non ammettono scorciatoie senza conseguenze sull'affidabilità dei gruppi risultanti. Una variabile espressa in euro con valori nell'ordine delle migliaia dominerà metriche di distanza come quella euclidea rispetto a variabili binarie o percentuali se non si procede a una standardizzazione; il risultato sarà che i cluster riflettono la scala delle variabili piuttosto che la struttura reale dei dati.
La riduzione della dimensionalità tramite PCA (Principal Component Analysis) o tecniche più recenti come UMAP è spesso necessaria quando il numero di variabili supera le decine: in spazi ad alta dimensionalità, la distanza euclidea perde progressivamente potere discriminante — fenomeno noto come "maledizione della dimensionalità" — e i cluster tendono a diventare indistinguibili. La selezione delle feature, d'altra parte, richiede un coinvolgimento diretto del dominio applicativo: clusterizzare i clienti di un retailer includendo variabili irrilevanti ai fini della segmentazione commerciale produce gruppi statisticamente coerenti ma inutilizzabili per decisioni operative. Qui emerge con chiarezza che il clusterizzare significato aziendale non è separabile dalla definizione precisa dell'obiettivo che si vuole raggiungere.
Validazione dei cluster e criteri di valutazione della soluzione
Uno degli errori più frequenti nelle analisi di clustering condotte in contesti aziendali è trattare l'output dell'algoritmo come definitivo senza sottoporre la soluzione a procedure di validazione; i cluster prodotti da qualsiasi algoritmo su qualsiasi dataset esistono, il problema è stabilire se riflettano una struttura reale nei dati o siano artefatti della scelta metodologica.
L'indice di silhouette misura, per ciascuna osservazione, quanto essa sia simile agli altri elementi del proprio cluster rispetto agli elementi del cluster più vicino: valori prossimi a 1 indicano un'assegnazione coerente, valori vicini a 0 suggeriscono ambiguità, valori negativi segnalano probabili errori di assegnazione. L'indice di Davies-Bouldin e il Calinski-Harabasz index forniscono misure complementari della separazione tra cluster e della compattezza interna; nessuno di questi indici è sufficiente da solo, e la pratica consolidata prevede di utilizzarli in combinazione.
La stabilità della soluzione di clustering verificata attraverso tecniche di bootstrap o eseguendo l'analisi su sottocampioni diversi del dataset è un criterio spesso trascurato ma metodologicamente più robusto degli indici di compattezza: una soluzione instabile, che cambia significativamente al variare del campione o dell'inizializzazione, non dovrebbe essere usata come base per decisioni strategiche, indipendentemente dai valori degli indici interni.
La validazione esterna, infine, consiste nel verificare se i cluster identificati correlino con variabili non incluse nell'analisi ma teoricamente rilevanti; se i segmenti di clientela prodotti dal clustering mostrano differenze significative nel tasso di riacquisto o nel lifetime value, variabili non usate per costruirli, questo rappresenta un'evidenza di validità predittiva che supera qualsiasi misura di coerenza interna.
Applicazioni concrete della clusterizzazione in contesti aziendali
Nel marketing e nella gestione della clientela, la segmentazione tramite clustering ha sostituito progressivamente le segmentazioni demografiche tradizionali, basate su variabili come età, genere o area geografica, con segmentazioni comportamentali che catturano pattern di utilizzo, frequenza di acquisto, sensibilità al prezzo e propensione a specifiche categorie di prodotto; la differenza in termini di potere predittivo e personalizzazione delle comunicazioni è misurabile e, in settori competitivi come retail, banking o telecomunicazioni, si traduce direttamente in metriche di conversione e retention. La segmentazione RFM (Recency, Frequency, Monetary value), che molte imprese conoscono e applicano in forma semplificata, diventa sostanzialmente più potente quando si abbandona la logica delle soglie fisse, che producono segmenti arbitrari, e si lascia che un algoritmo di clustering identifichi i gruppi naturali nello spazio tridimensionale delle tre variabili.
In ambito operativo e di supply chain, la clusterizzazione degli SKU (Stock Keeping Unit) per profilo di domanda permette di differenziare le politiche di gestione delle scorte in modo coerente con la volatilità effettiva di ciascun gruppo, riducendo sia i costi di magazzino che i rischi di stockout; analogamente, la clusterizzazione geografica dei punti di consegna ottimizza la progettazione dei giri logistici con benefici diretti sui costi di trasporto.
Nel monitoraggio della qualità e nella manutenzione predittiva, algoritmi come DBSCAN sono applicati su serie temporali di segnali sensoriali per identificare pattern anomali che precedono guasti, permettendo interventi preventivi prima che il deterioramento diventi critico. La trasversalità delle applicazioni rende il clusterizzare significato operativo molto più ampio della sola segmentazione commerciale con cui il termine è spesso associato.
Limiti strutturali e condizioni per un uso affidabile
La clusterizzazione è una tecnica esplorativa, non confermativa: non verifica ipotesi, non stabilisce relazioni causali, non produce previsioni nel senso statistico del termine; i cluster identificati sono descrizioni della struttura presente nei dati osservati, e la loro utilità dipende interamente dalla capacità dell'organizzazione di tradurli in azioni differenziate e misurabili.
Questa distinzione ha conseguenze pratiche rilevanti: affidarsi ai cluster come se fossero categorie oggettive e permanenti trattando la segmentazione prodotta sei mesi prima come ancora valida senza riverifica porta a decisioni basate su una fotografia invecchiata della realtà, particolarmente problematica in mercati con dinamiche rapide.
La dipendenza dai dati disponibili introduce un secondo ordine di limitazioni: se le variabili raccolte dall'impresa non catturano le dimensioni effettivamente rilevanti per differenziare i comportamenti perché i sistemi informativi sono stati progettati per scopi amministrativi piuttosto che analitici i cluster risultanti saranno una segmentazione di ciò che è misurabile, non necessariamente di ciò che è significativo.
Investire nella qualità e nella pertinenza della raccolta dati prima di investire nell'algoritmo è una priorità metodologica che molte organizzazioni invertono, con risultati analiticamente corretti ma strategicamente sterili. La maturità analitica di un'impresa si misura anche dalla capacità di riconoscere questi limiti e di costruire processi in cui la clusterizzazione è uno strumento ricorrente, verificato e aggiornato, non un progetto una tantum che produce un output usato per anni senza interrogarsi sulla sua persistente validità.
Leggi anche:
Certificazioni di qualità per le imprese: ISO 9001 e le altre che aprono mercati esteri
Articolo Precedente
MES o Manufacturin Execution System: significato e funzionamento del sistema
Articolo Successivo
Logistica sostenibile: strategie operative 2026

Autrice di articoli per blog, laureata in Psicologia con la passione per la scrittura e le guide How to


